The agent runtime event model
Four runtime events, four policy-attachment surfaces, and the hook coverage at each event is what separates a demo from something a regulated buyer will sign for. Framework selection is a distraction.
The framework wars are a distraction
Engineers keep asking me which agent framework to pick. LangChain or CrewAI or roll-your-own. It's the wrong question to lead with. The architectural choice that actually compounds isn't framework selection. It's where you can attach policy inside your agent runtime.
Every production agent stack I've shipped over the last eighteen months converged on the same answer: four runtime events, four policy-attachment surfaces, and the hook coverage at each event is what separates a demo from something a regulated buyer will sign for.
Here is the taxonomy, the bug class each event prevents, and a three-question audit you can run on any agent stack this week.
What an event model is
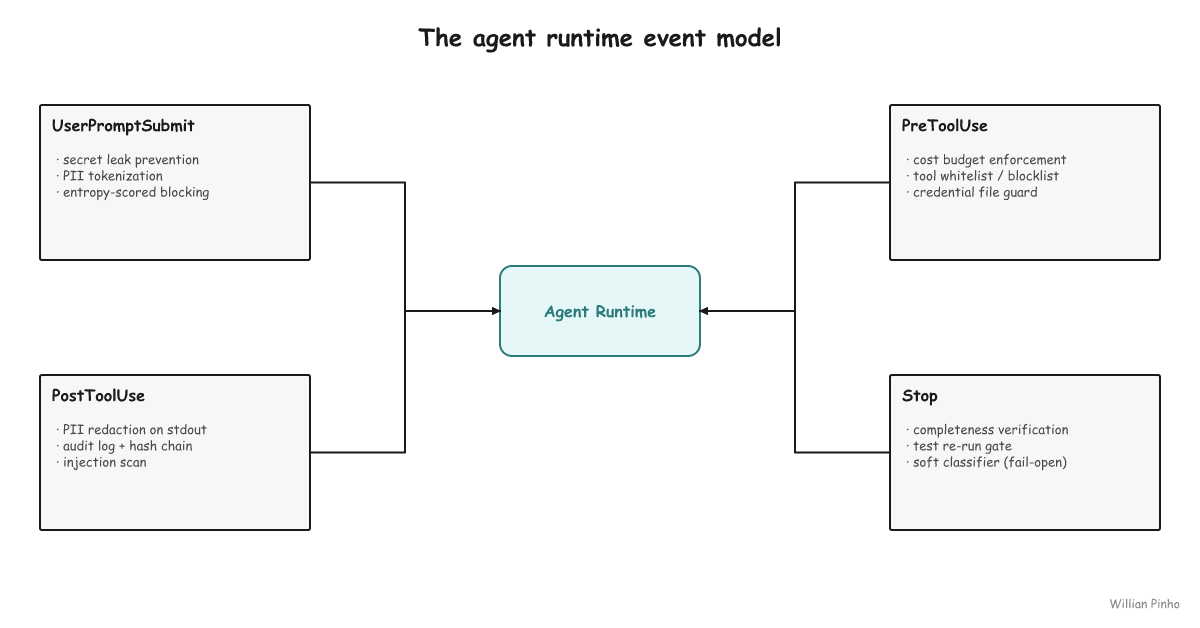
Every production agent runtime worth shipping exposes a small set of policy-attachment events. The taxonomy below comes from Claude Code's hook model, a developer-side agent runtime I work in daily: UserPromptSubmit, PreToolUse, PostToolUse, Stop. I've adopted the same four-event model in the server-side agent stack my SaaS runs, mapped onto its runtime. The names are Claude Code's; the architectural pattern is what's portable. LangChain calls the analogous surfaces on_chat_model_start / on_tool_start / on_tool_end / on_agent_finish; OpenAI's Agents SDK calls them on_agent_start / on_tool_start / on_tool_end / on_agent_end. The names differ. The attachment surfaces, and the bugs they prevent, are the same.
UserPromptSubmit— before the prompt reaches the model.PreToolUse— before the agent's chosen tool fires.PostToolUse— after the tool returns, before the model sees the output.Stop— after the agent says "done".
Each event is a policy-attachment surface with its own semantics, and the differences are what you design around. The latency budget varies: UserPromptSubmit must run in single-digit milliseconds because it sits on the user's input path, while Stop can take a full second because the user has already submitted and is reading. That gap is why the input-path events can't run a synchronous deep check — you fail fast there and save the real verification for Stop, where you can afford it. The failure modes differ too when a hook blocks. So does the data shape: the prompt event sees raw user text, the pre-tool event sees the planned tool invocation, the post-tool event sees the tool's return payload, and the stop event sees the full transcript.
The architectural question isn't "which framework". It's "which of these four events does my runtime actually expose, and what policy coverage do I have at each one?".
It sits closer to an aspect-oriented interceptor than to Express middleware, though neither maps cleanly. Middleware composes around a fixed request-response shape; an AOP interceptor wraps one method call. A hook attaches at a named lifecycle event defined by the runtime, the runtime's dispatcher decides when and whether you fire, the payload shape is event-specific, and your only contract is exit code and mutated payload.
One thing the framework cannot decide for you: what happens when the hook itself crashes. PII redactors and secret-leak blockers must fail closed, better a denied request than a leaked credential. Completeness verifiers should fail open when they gate a plain response, a crashed classifier should not block the user from getting one. The exception proves the rule: when "done" gates a destructive action like a migration or a deploy, fail closed and alert instead. The hook's failure mode is policy, not infrastructure. Get this wrong and you ship either a security hole or a denial-of-service.
What class of bug each event prevents
UserPromptSubmit
This event hard-blocks secrets in prompts using pattern matching plus entropy scoring for unknown formats, with provider verification on the high-value patterns (Stripe, AWS, GitHub) when latency budget allows. A canary token seeded in your secret stores catches the rare leak that slips both: if that token ever shows up in a submitted prompt, a real credential took the same path. It tokenizes PII into reversible placeholders so the model reasons over ⟪PII_email_42⟫ instead of the real address. The receipt: a class of credential leak that slipped past code review three times in one week on a SaaS I'm shipping stopped being possible once this was wired in. The hook returns exit 2 and the prompt never reaches the provider. Same leak, caught at the runtime instead of in a review someone has to remember to do.
PreToolUse
Cost-budget enforcement at tool-call granularity: per-day, per-task, per-tool. Blocklist enforcement on file reads (no .env*, no credential files, no rendered config with secrets baked in). Tool whitelisting in adversarial or untrusted-input contexts. This is the event that turns "the agent can do anything" into "the agent can do what its policy allows". One caveat worth stating plainly: this is a policy boundary, not an isolation boundary. For genuinely untrusted code execution you still want OS-level sandboxing (gVisor, Firecracker) underneath — the hook decides what's allowed, the sandbox contains what goes wrong.
PostToolUse
PII redaction on stdout before the model ingests the tool output. A compliance audit log with a hash chain you can hand to a security reviewer. Injection-scan: tool outputs that look like prompt injections get stripped before they re-enter the conversation, which closes a class of indirect prompt injection that pure system-prompt defense cannot reach.
Stop
Completeness verification. A small classifier reads the user's items and asks whether each one got addressed. In our deployment, after about two weeks of tuning, the false-positive rate settled near 8% — so we treat it as a soft warning, not a hard block. The math is forgiving: a small classifier runs at roughly $0.001/turn (Haiku pricing, ~500 input tokens), so catching even one in twenty "I'll do that next" slop patterns covers the cost many times over. Test re-run gating also lives here, before the agent declares done.
Why this beats framework selection
Hooks are framework-agnostic. The contract is the runtime event, not the framework API. Swap one framework for another and the policy logic you wired in still applies — you rewrite the thin integration glue that extracts each runtime's payload, not the policies themselves. That's a fraction of a full re-architecture.
The economic argument is sharper. Framework choice is a decision you'll revisit as the ecosystem churns — new entrants, better abstractions, a migration every couple of years. Hook coverage outlives all of that, because the four events stay put even as the policies you attach to them keep growing.
OWASP's first LLM Top 10 in 2023 already flagged this, and the 2025 update sharpened it. Four of the ten items — Prompt Injection (LLM01), Sensitive Information Disclosure (LLM02), Improper Output Handling (LLM05), Excessive Agency (LLM06) — are runtime-control problems. None of them is a framework-selection problem. The conversation moved one layer down, to where you can actually attach policy.
A three-question audit
Three questions for any production agent stack:
- Which event does your secret-leak prevention attach to? If none, you are shipping with a known leak surface every team has crossed at least once. (OWASP LLM02: Sensitive Information Disclosure.)
- Which event catches completion lies, agent says done when it is not? If none, user trust erodes invisibly until churn spikes and you cannot trace why. (No OWASP entry yet. This is the gap the standard has not caught up to.)
- Which event audits tool outputs for PII before the model reingests them? If none, regulated industries cannot deploy your stack regardless of how impressive the demo is. (OWASP LLM02 + LLM05: Improper Output Handling.)
Frameworks are a commodity. Your hook coverage is the moat.
Sources
- Claude Code Hooks reference — https://code.claude.com/docs/en/hooks
- LangChain Callbacks (BaseCallbackHandler) — https://reference.langchain.com/python/langchain-core
- OWASP Top 10 for LLM Applications 2025 — https://genai.owasp.org/llm-top-10/
- NIST AI Risk Management Framework — https://www.nist.gov/itl/ai-risk-management-framework
- Microsoft Presidio Anonymizer — https://microsoft.github.io/presidio/anonymizer/
- Trufflehog — https://github.com/trufflesecurity/trufflehog
- Greshake et al., "Not what you've signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection" — https://arxiv.org/abs/2302.12173
- Anthropic Claude pricing — https://platform.claude.com/docs/en/about-claude/pricing